 We stand with our friends and colleagues in Ukraine.
To support Ukraine in their time of need
We stand with our friends and colleagues in Ukraine.
To support Ukraine in their time of need
Architecture
See also:
Terminology
Jaeger represents tracing data in a data model inspired by the OpenTracing Specification.
Span
A span represents a logical unit of work that has an operation name, the start time of the operation, and the duration. Spans may be nested and ordered to model causal relationships.
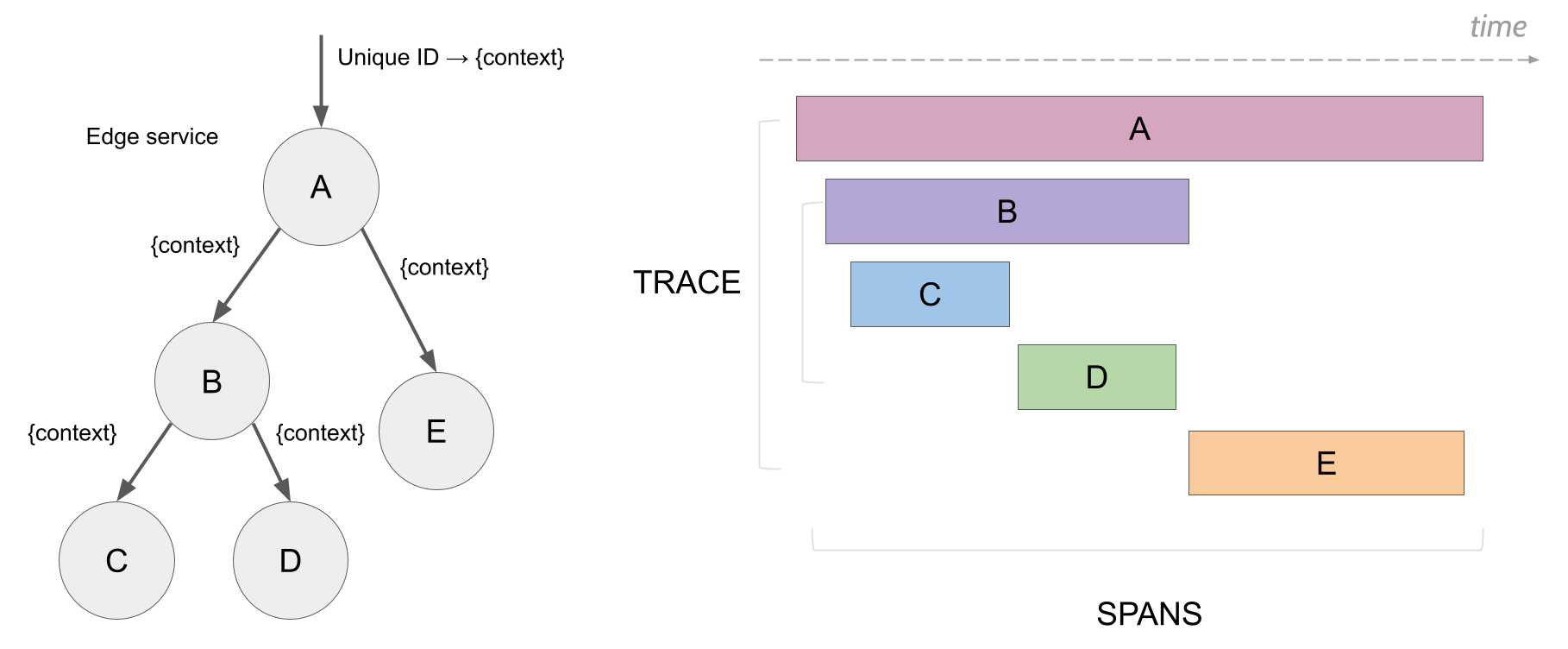
Trace
A trace represents the data or execution path through the system. It can be thought of as a directed acyclic graph of spans.
Baggage
Baggage is arbitrary user-defined metadata (key-value pairs) that can be attached to distributed context and propagated by the tracing SDKs. See W3C Baggage for more information.
Components
Jaeger can be deployed either as an all-in-one binary, where all Jaeger backend components run in a single process, or as a scalable distributed system, discussed below. There are two main deployment options:
- Collectors are writing directly to storage.
- Collectors are writing to Kafka as a preliminary buffer.
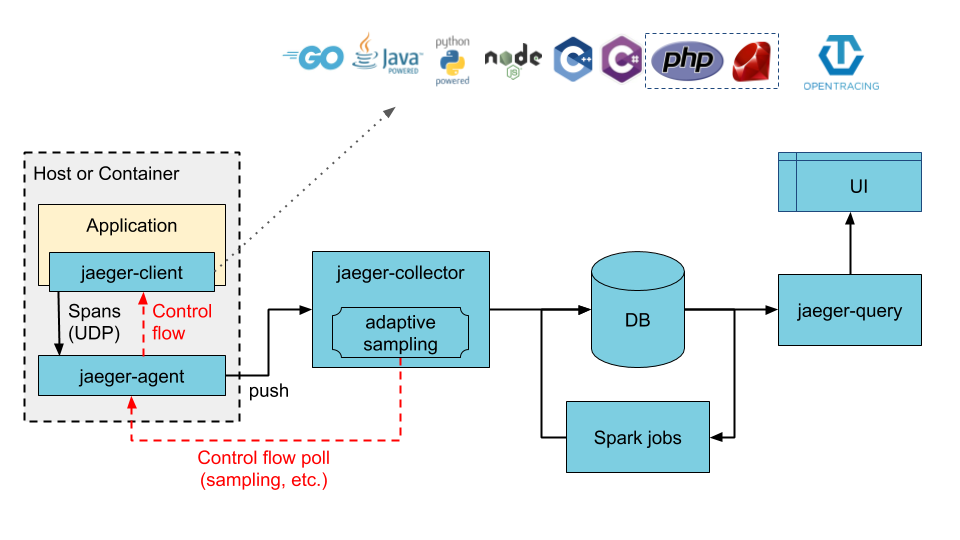 Illustration of direct-to-storage architecture
Illustration of direct-to-storage architecture
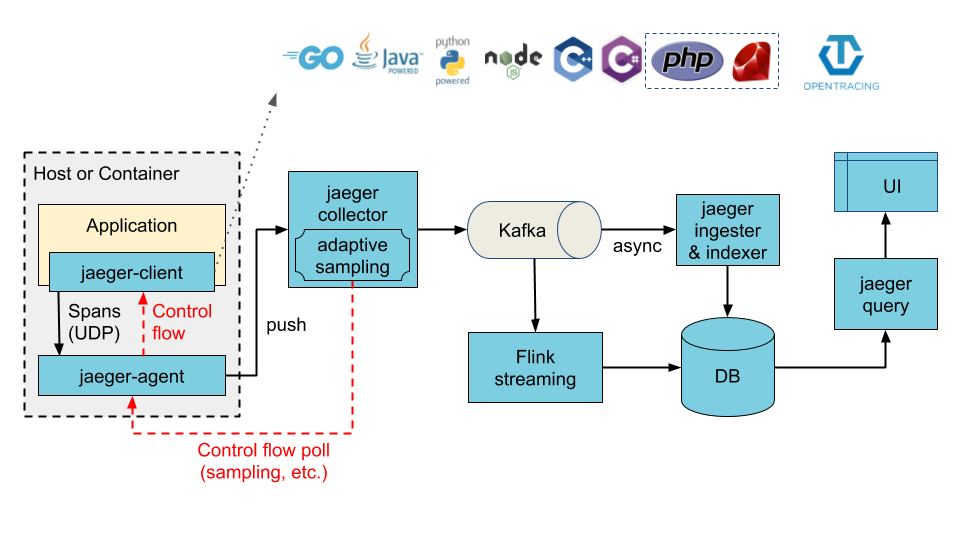 Illustration of architecture with Kafka as intermediate buffer
Illustration of architecture with Kafka as intermediate buffer
This section details the constituent parts of Jaeger and how they relate to each other. It is arranged by the order in which spans from your application interact with them.
Jaeger client libraries (deprecated)
Jaeger clients are language specific implementations of the OpenTracing API. They can be used to instrument applications for distributed tracing either manually or with a variety of existing open source frameworks, such as Flask, Dropwizard, gRPC, and many more, that are already integrated with OpenTracing.
An instrumented service creates spans when receiving new requests and attaches context information (trace id, span id, and baggage) to outgoing requests. Only the ids and baggage are propagated with requests; all other profiling data, like operation name, timing, tags and logs, is not propagated. Instead, it is transmitted out of process to the Jaeger backend asynchronously, in the background.
The instrumentation is designed to be always on in production. To minimize the overhead, Jaeger clients employ various sampling strategies. When a trace is sampled, the profiling span data is captured and transmitted to the Jaeger backend. When a trace is not sampled, no profiling data is collected at all, and the calls to the OpenTracing APIs are short-circuited to incur the minimal amount of overhead. By default, Jaeger clients sample 0.1% of traces (1 in 1000), and have the ability to retrieve sampling strategies from the Jaeger backend. For more information, please refer to Sampling.
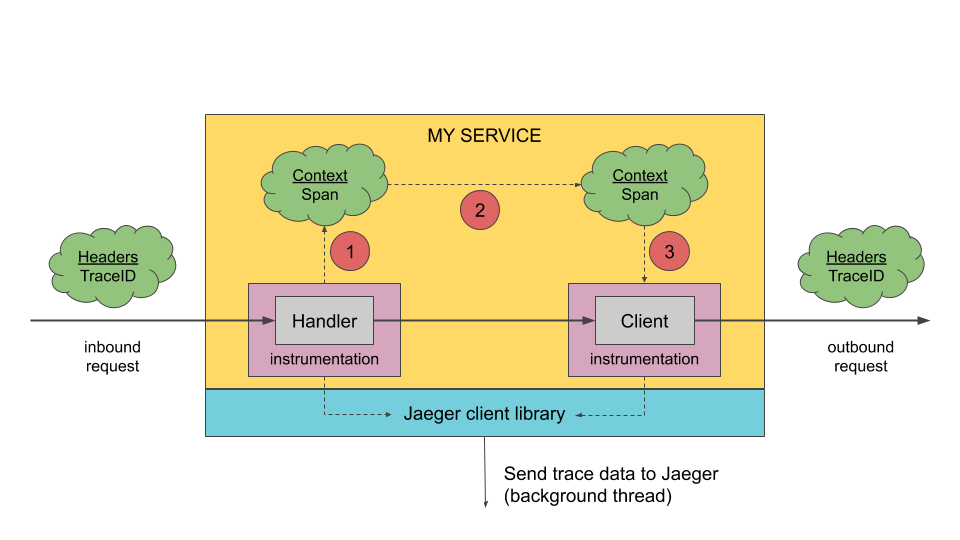 Illustration of context propagation
Illustration of context propagation
Agent
The Jaeger agent is a network daemon that listens for spans sent over UDP, which are batched and sent to the collector. It is designed to be deployed to all hosts as an infrastructure component. The agent abstracts the routing and discovery of the collectors away from the client.
The agent is not a required component. For example, when your applications are instrumented with OpenTelemetry, the SDKs can be configured to forward the trace data directly to Jaeger collectors.
Collector
The Jaeger collector receives traces from the SDKs or Jaeger agents, runs them through a processing pipeline for validation and clean-up/enrichment, and stores them in a storage backend.
Jaeger comes with built-in support for several storage backends (see Deployment), as well as extensible plugin framework for implementing custom storage plugins.
Query
The Jaeger query is a service that exposes the APIs for retrieving traces from storage and hosts a Web UI for searching and analyzing traces.
Ingester
The Jaeger ingester is a service that reads traces from Kafka and writes them to a storage backend. Effectively, it is a stripped-down version of the Jaeger collector that supports Kafka as the only input protocol.